
에 의해 게시 David Gradwell
1. Moving the fuzziness slider one notch towards ‘fuzzy’ will result in a case-insensitive comparison – e.g. ‘DAVE’ will be treated as a duplicate of ‘Dave’.
2. Moving the slider another notch towards ‘fuzzy’ will result in a spelling-insensitive comparison – e.g. ‘Jenni’ will be treated as a duplicate of ‘Jenny’.
3. Moving the slider all the way towards ‘fuzzy’ will greatly reduce the strictness of the matching algorithm – e.g. ‘Bob’ will be treated as a duplicate of ‘Bobby’.
4. With some experimentation on the range between ‘strict’ and ‘fuzzy’, the operator should find a satisfactory level of deduplication.
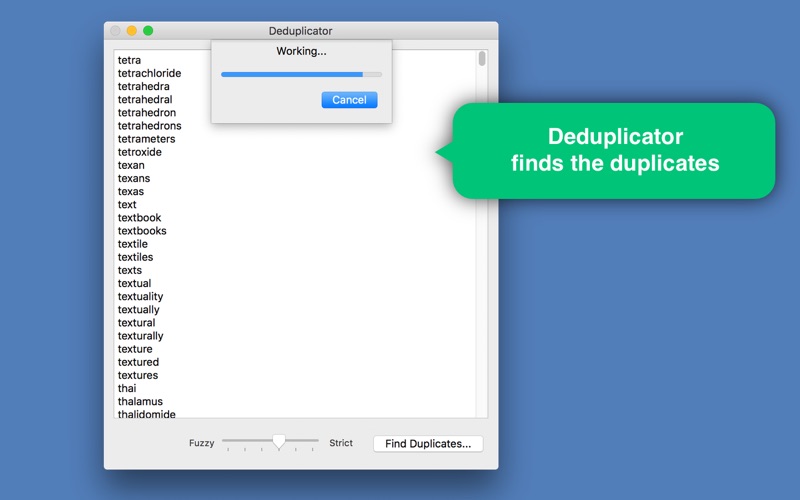
5. Deduplicator will identify duplicate items and show them in a preview window.
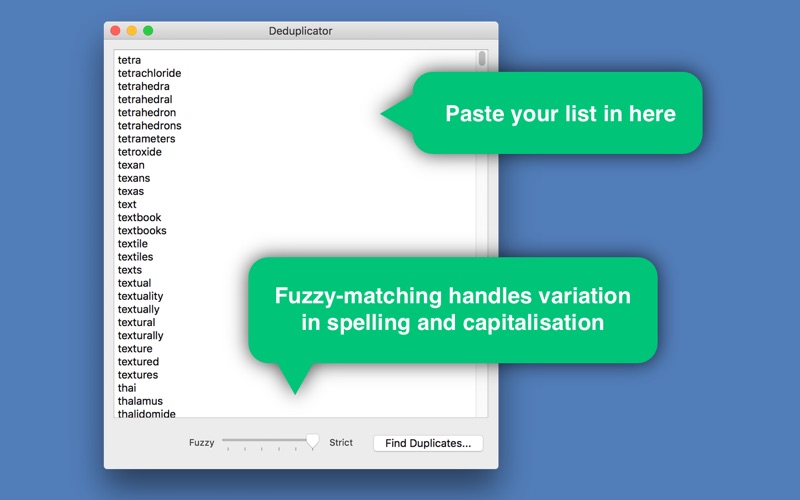
6. Simply paste your list into Deduplicator and hit ‘Find Duplicates’.
7. To account for variation in capitalisation and spelling, you may wish to use fuzzy matching.
8. Your list has now been deduplicated and contains only unique elements.
9. Hit ‘Remove Duplicates’ to proceed.

또는 아래 가이드를 따라 PC에서 사용하십시오. :
PC 버전 선택:
소프트웨어 설치 요구 사항:
직접 다운로드 가능합니다. 아래 다운로드 :
설치 한 에뮬레이터 애플리케이션을 열고 검색 창을 찾으십시오. 일단 찾았 으면 Deduplicator 검색 막대에서 검색을 누릅니다. 클릭 Deduplicator응용 프로그램 아이콘. 의 창 Deduplicator Play 스토어 또는 앱 스토어의 스토어가 열리면 에뮬레이터 애플리케이션에 스토어가 표시됩니다. Install 버튼을 누르면 iPhone 또는 Android 기기 에서처럼 애플리케이션이 다운로드되기 시작합니다. 이제 우리는 모두 끝났습니다.
"모든 앱 "아이콘이 표시됩니다.
클릭하면 설치된 모든 응용 프로그램이 포함 된 페이지로 이동합니다.
당신은 아이콘을 클릭하십시오. 그것을 클릭하고 응용 프로그램 사용을 시작하십시오.
다운로드 Deduplicator Mac OS의 경우 (Apple)
| 다운로드 | 개발자 | 리뷰 | 평점 |
|---|---|---|---|
| $3.99 Mac OS의 경우 | David Gradwell | 0 | 1 |
Removes duplicates from a list. Simply paste your list into Deduplicator and hit ‘Find Duplicates’. Deduplicator will identify duplicate items and show them in a preview window. Hit ‘Remove Duplicates’ to proceed. Your list has now been deduplicated and contains only unique elements. To account for variation in capitalisation and spelling, you may wish to use fuzzy matching. Moving the fuzziness slider one notch towards ‘fuzzy’ will result in a case-insensitive comparison – e.g. ‘DAVE’ will be treated as a duplicate of ‘Dave’. Moving the slider another notch towards ‘fuzzy’ will result in a spelling-insensitive comparison – e.g. ‘Jenni’ will be treated as a duplicate of ‘Jenny’. Moving the slider all the way towards ‘fuzzy’ will greatly reduce the strictness of the matching algorithm – e.g. ‘Bob’ will be treated as a duplicate of ‘Bobby’. With some experimentation on the range between ‘strict’ and ‘fuzzy’, the operator should find a satisfactory level of deduplication. Please feel free to contact me with any enquiries or feedback -- info@bonhardcomputing.com

Tagpad - add hashtags to your notes

Playall - ad blocker & player
Deduplicator

Folder Snapshot Utility

Rsync Server - Basic Edition

Google Chrome

네이버 MYBOX - 네이버 클라우드의 새 이름

유니콘 HTTPS(Unicorn HTTPS)

T전화

Samsung Galaxy Buds
Google Authenticator

앱프리 TouchEn Appfree

전광판 - LED전광판 · 전광판어플

Samsung Galaxy Watch (Gear S)

Fonts

Whale - 네이버 웨일 브라우저

네이버 스마트보드 - Naver Smartboard

Pi Browser

더치트 - 사기피해 정보공유 공식 앱
 PcMac 한국어
PcMac 한국어